人臉辨識想要達到準確度高、辨識速度也要快,在大多的模型都利用較深的層數來強化模型的準確度,在2017年所出現的MobileNet模型是利用depthwise separable convolution來化簡參數個數,來達到減少原始convolution的計算量,在不降低太多原本利用捲積層的效果。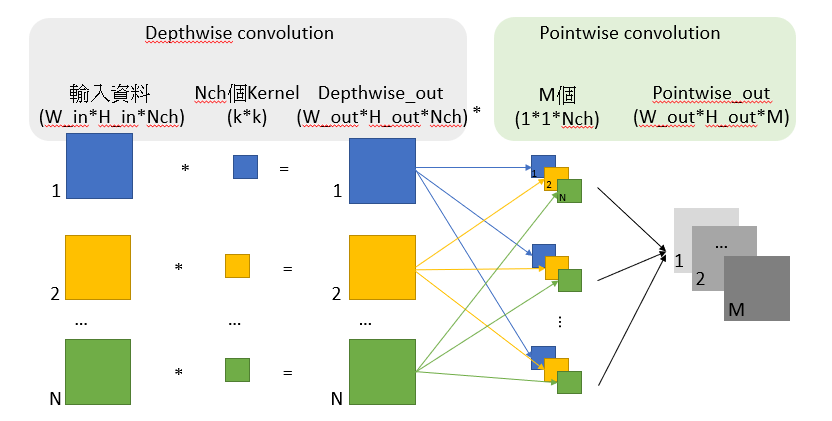
舉例說明:Input (16,16,16) output(16,16,64) kernel size(3,3)
Original convolution
= K x K x Nch x M x W_in x H_in
= 3 x 3 x 16 x 64 x 16 x 16 = 2359296
Depthwise separable convolution
= K x K x Nch x W_in x H_in+ Nch x M x W_in x H_in
= 3 x 3 x 16 x 16 x 16 + 16 x 64 x 16 x 16
= 36864 + 262144 = 299008
這樣參數量從原先的2359296降低到299008
比例為299008/2359296=0.126
在Pointwise convolution為何1 x 1 x Nch是使用1呢?
因為在每一個Feature map與其他Feature map的關聯性要有所連接,乘1的話所有的Feature map關聯性較容易進行組合生成新的Feature map。

